


Today, ridley (the server, not the villain from Metroid) had its first major unexpected downtime incident. Following is a reconstruction of events. All times are given in UTC.
- 26 April 2013, approximately 18:01 – All connections between ridley and the outside world mysteriously drop. Icinga notices this and reports it as issues connecting to phazon for service and host checks.
- 18:05 – The Icinga event log suddenly cuts, and I can only interpret this as the Linode server that hosts ridley (Fremont586) and other systems either crashing or shutting down. Either way, ridley was hard-stopped.
- 18:06 – I notice the issue and attempt to connect to ridley by SSH and eventually through LISH, but to no avail – I can’t even contact the host server.
- approximately 18:15 – I connect to the #linode IRC channel and discover that this is a large scale problem affecting many, many customers with Linodes in Fremont.
- 18:20 – Linode posts their first update to their Status Blog, “We’ve been alerted to a network connectivity issue affecting the Fremont facility at this time. We are currently in the process of investigating and will provide more information as it becomes available.”
- 18:28 – I post the first details (1, 2, 3) to @LizardWiki’s Twitter.
- approximately 18:30 – Users in #linode reporting intermittent connectivity to their Fremont Linodes, but ridley is still completely unreachable – 100% packet loss from phazon since I first noticed my connections drop.
- 18:46 – Pings start arriving from ridley to phazon. Icinga reports that at 18:46:29 that it had cold-started. Server cold-boots, and according to the Linode Manager the boot is “host initiated”. I begin damage control.
- 18:50 – I report on @LizardWiki’s Twitter that the server now appears to be up.
- 19:20 – Linode Status reports, “We’re still working on resolving the connectivity issues being experienced at our Fremont facility. At this time there is no ETA for full resolution. Once more information is available we’ll be providing an update here.”
- 19:45 – Linode Status finally reports, “The networking issue should be resolved at this time. If you continue to experience any problems please open a support ticket from within the Linode Manager.”
- 20:01 – I report on @LizardWiki’s Twitter that the server is stable and the downtime is over.
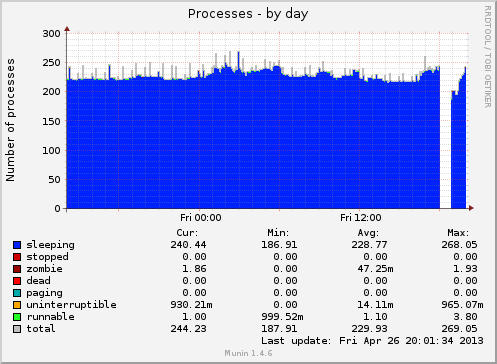
Munin “Processes by day” graph. Note the gap around 18:00 UTC indicating the downtime period when no data could be accounted (since the server was down).
According to Pingdom, the downtime lasted a total of approximately 45 minutes, consistent with the figure shown to the right.
There appears to have been no serious permanent damage caused by the downtime, although the server was hard-halted when the host system was shutdown or crashed (unclear which). There was some damage to the MySQL databases, but `mysqlcheck` handled that with no issues. Munin had some issues with plugins on ridley after the reboot, but that has been fixed as well as a strange error with Rav3nZNC related to the ident module. Gerrit was extremely slow to start up after the reboot, causing the control application to erroneously signal failure, but it did in fact start up correctly with no errors, and a restart of Gerrit confirmed this with an OK signal. At this time, all services on ridley appear to be up and stable and Icinga reports no problems with ridley. Although the downtime was caused by factors well beyond my (and probably everyones’) control, I apologize for the inconvenience this has caused. As always, if you have any questions please feel free to post a comment here or contact me directly. Users of ridley should contact me directly if they notice any damage to their files or if they notice any services not working properly.
Linode has not yet posted a detailed postmortem, but this post will be updated if/when one becomes available.
UPDATE, 5:45 29 April 2013 (UTC): Linode has released their postmortem on the situation, and you can find that as well as their timeline of events here. In addition, I received a support ticket in my Linode manager that ridley’s host was rebooted for emergency maintenance, explaining the cold boot of ridley.
Thank you for flying LizardNet!
